前面分别看了lambda表达式的定义、Stream接口的使用以及Collectors的应用,对如何使用Java 8里面提供的函数式机制有了一定了解,这里回过头了解下相应的代码实现,梳理下Stream的执行脉络。
从一个简单的示例来看下Stream执行过程是如何实现的,
Stream.of(1, 2, 3).map(x -> x + 1).filter(x -> x > 2).reduce((x, y) -> x + y).ifPresent(System.out::println);
Stream的构造
Pipeline
首先是Stream的创建,Stream.of(1, 2, 3),Stream.of其代码实现内部是调用了Arrays.stream,
public static<T> Stream<T> of(T... values) {
return Arrays.stream(values);
}
Arrays.stream里调用了,
public static <T> Stream<T> stream(T[] array) {
return stream(array, 0, array.length);
}
public static <T> Stream<T> stream(T[] array, int startInclusive, int endExclusive) {
return StreamSupport.stream(spliterator(array, startInclusive, endExclusive), false);
}
public static <T> Stream<T> stream(Spliterator<T> spliterator, boolean parallel) {
Objects.requireNonNull(spliterator);
return new ReferencePipeline.Head<>(spliterator, StreamOpFlag.fromCharacteristics(spliterator), parallel);
}
这部分代码告诉我们RefrerencePipeline是实际处理逻辑的实现类,与Stream接口区分了原生类型与引用类型一样,Pipeline也有对应的实现,
- ReferencePipeline
- IntPipeline
- LongPipeline
- DoublePipeline
不同Pipeline的处理逻辑大致相同,只要弄明白一个,其余的也就清楚了。
Spliterator
在构造Pipeline的时候需要传入Spliterator,这个东西也是之前版本中所没有的。Spliterator实际负责了如何从数据源中获取数据的责任,其定义如下,
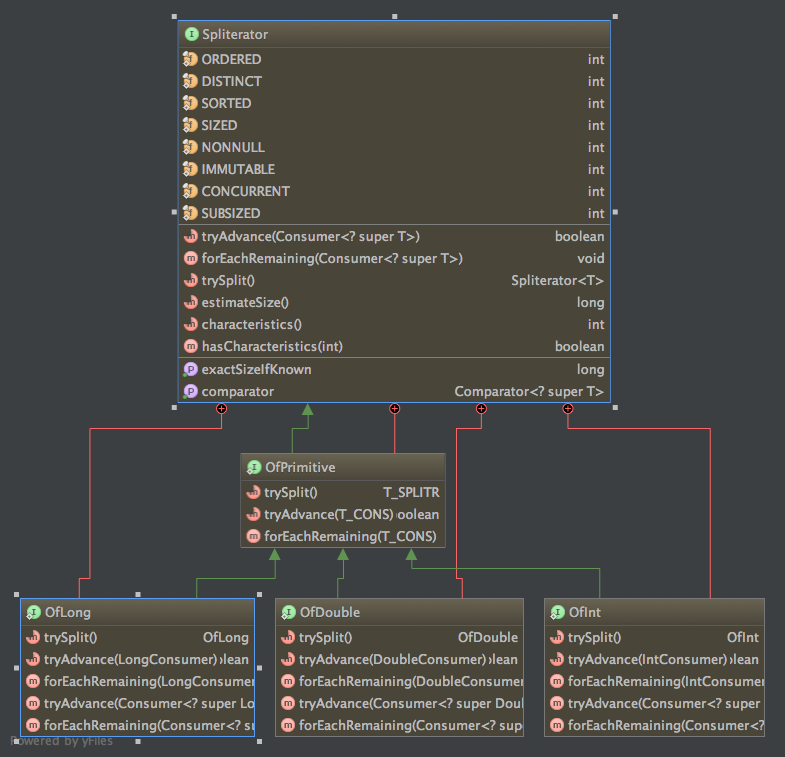
需要注意的是其中定义的tryAdvance、forEachRemaining两个接口。在Pipeline执行过程中会通过这两个接口来实际获得数据。
map/filter的实现
map、filter虽然是两个不同的接口,但其内部流程比较相似,这里就一并来看下,
public final <R> Stream<R> map(Function<? super P_OUT, ? extends R> mapper) {
Objects.requireNonNull(mapper);
return new StatelessOp<P_OUT, R>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SORTED | StreamOpFlag.NOT_DISTINCT) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<R> sink) {
return new Sink.ChainedReference<P_OUT, R>(sink) {
@Override
public void accept(P_OUT u) {
downstream.accept(mapper.apply(u));
}
};
}
};
}
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}
map、reduce两个函数调用均返回了StatelessOp,这里可以验证文档里说的Stream提供的接口操作分为intermediate/terminal两种操作,intermediate操作调用后并不会执行传入的操作。所有的intermediate返回的都是StatelessOp/StatefulOp。StatelessOp/StatefulOp又是什么呢?这两个也是继承自Pipeline的,所以intermidate操作返回的都是Stream。
ChainedReference也是需要注意的一个类,通过它构建了Pipeline的不同阶段,在AbstractPipeline可以看到如下变量用以记录。
private final AbstractPipeline sourceStage;
private final AbstractPipeline previousStage;
private AbstractPipeline nextStage;
reduce的实现
reduce操作则是terminal操作,
// ReferencePipeline.java
public final Optional<P_OUT> reduce(BinaryOperator<P_OUT> accumulator) {
return evaluate(ReduceOps.makeRef(accumulator));
}
// AbstractReferencePipeline.java
final <R> R evaluate(TerminalOp<E_OUT, R> terminalOp) {
assert getOutputShape() == terminalOp.inputShape();
if (linkedOrConsumed)
throw new IllegalStateException(MSG_STREAM_LINKED);
linkedOrConsumed = true;
return isParallel()
? terminalOp.evaluateParallel(this, sourceSpliterator(terminalOp.getOpFlags()))
: terminalOp.evaluateSequential(this, sourceSpliterator(terminalOp.getOpFlags()));
}
// ReduceOps.java
public static <T, U> TerminalOp<T, U>
makeRef(U seed, BiFunction<U, ? super T, U> reducer, BinaryOperator<U> combiner) {
Objects.requireNonNull(reducer);
Objects.requireNonNull(combiner);
class ReducingSink extends Box<U> implements AccumulatingSink<T, U, ReducingSink> {
@Override
public void begin(long size) {
state = seed;
}
@Override
public void accept(T t) {
state = reducer.apply(state, t);
}
@Override
public void combine(ReducingSink other) {
state = combiner.apply(state, other.state);
}
}
return new ReduceOp<T, U, ReducingSink>(StreamShape.REFERENCE) {
@Override
public ReducingSink makeSink() {
return new ReducingSink();
}
};
}
上面这么一大段内容就是其中一个reduce接口涉及的代码。这段内容里面需要注意ReduceOps这个类。在Java 8中几乎每一个terminal操作都有这么个对应的类,
- DistinctOps
- FindOps
- ForEachOps
- MatchOps
- ReduceOps
- SliceOps
- SortedOps
这些Ops内部实现在流程上都很类似。同样的,弄明白ReduceOps基本也就能弄明白其余的。最终执行reduce逻辑的代码是哪呢,在ReduceOps.java的ReduceOp类中,
private static abstract class ReduceOp<T, R, S extends AccumulatingSink<T, R, S>> implements TerminalOp<T, R> {
private final StreamShape inputShape;
ReduceOp(StreamShape shape) {
inputShape = shape;
}
public abstract S makeSink();
@Override
public StreamShape inputShape() {
return inputShape;
}
@Override
public <P_IN> R evaluateSequential(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return helper.wrapAndCopyInto(makeSink(), spliterator).get();
}
@Override
public <P_IN> R evaluateParallel(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return new ReduceTask<>(this, helper, spliterator).invoke().get();
}
}
最后的实现逻辑实在AbstractPipeline.java中,
@Override
final <P_IN, S extends Sink<E_OUT>> S wrapAndCopyInto(S sink, Spliterator<P_IN> spliterator) {
copyInto(wrapSink(Objects.requireNonNull(sink)), spliterator);
return sink;
}
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}
Sink.java也是需要关注的接口,在最终执行过程中均是通过这个接口来操作数据的,
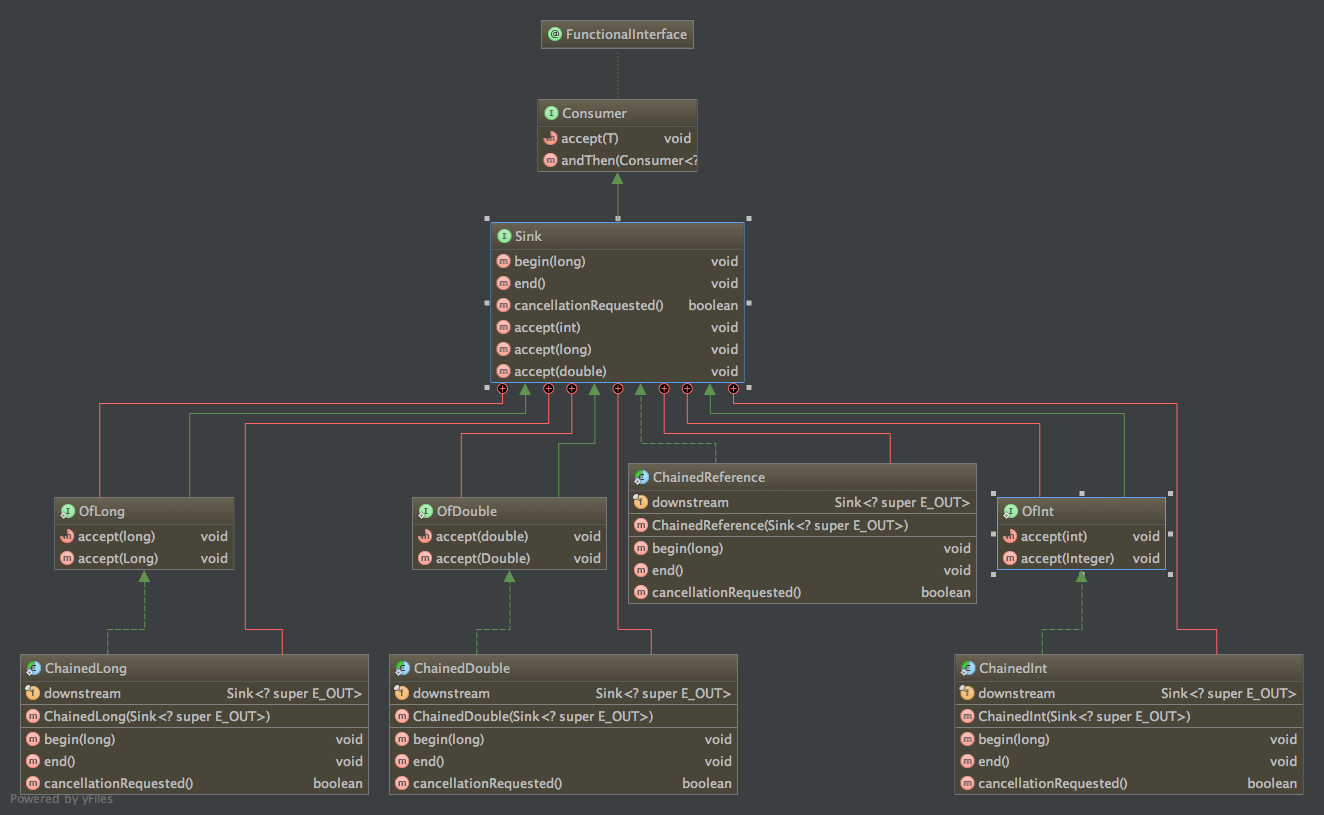
总结
Java的一大好处就是代码开源可以随便看,而且其大部分库都是Java语言实现的,这样读起来也不费劲,不像Python需要去看C++代码。阅读Stream执行过程的相关代码,对其特性会有进一步认识,比如就更容易理解为什么会有intermediate/terminal操作的区分,以及也可以去看下Stream的并行是如何实现的,应该是应用了ForkJoin框架。
比较大的一个感受就是Java 8中区分了IntStream、LongStream、DoubleStream、ReferenceStream,相关联的实现也基本就是四份,实现上来看相当冗余。如果Java能更好更有效率的处理原生类型,这部分代码实现就可以简化。
在实际开发中知道如何使用往往并不足够,能够了解底层的实现通常会对使用更有帮助。退一步说,看看这些代码也可以了解下JDK的实现者们是如何进行抽象设计的,或多或少也能学到点东西。